
Resumen rápido
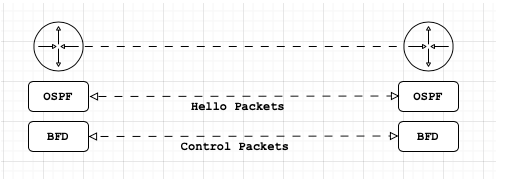
BFD es un protocolo de red que detecta fallas de link en milisegundos, o incluso microsegundos. Los protocolos de ruteo como OSFP o BGP tienen sus propios mecanismos de detección de fallas, sin embargo los tiempos soy mucho mayores. Por ejemplo;
OSPF utiliza los paquetes «hello» y un hold timer. Los paquetes de «hello» se envían de forma automática cada 10 segundos, cuando el equipo vecino deja de recibir estos paquetes por 40 segundos, entonces, se declara la vecindad muerta. Es decir, tomaría al rededor de 40 segundos, detecta una falla en ese link.
BGP utiliza hasta 180 segundos en poder detectar una falla con su peer.
Contexto
Como bien sabemos, cada unos de los protocolos de enrutamiento cuentan con sus propios timers, y si bien es posible que estos pueden ser modificados buscando una detección de falla mucho más rápido, también, es cierto que los protocolos no fueron creados con ese propósito. Y algo aún mas interesante y preocupante, los paquetes de comunicación de todos los protocolos son envían en el plano de control, esto significa que, si nosotros aumentamos la periodicidad de envió de estos paquetes, la carga del CPU de nuestro equipo de red, será mucho mayor.
BFD trabaja de forma independiente al protocolo de ruteo (OSPF, BGP, HSRP, etc). Una vez configurado es posible configurar el protocolo de ruteo. Para tener una contexto más amplio, explicaremos lo siguiente.
Existen dos modos de operación de BFD; Asíncrono y por demanda
El modo asíncrono es muy similar al proceso de OSPF con hellos y dead intervals, BFD envía paquetes de control y cuando estos dejan de ser recibidos la sesión se termina.
El modo baja demanda trabaja de forma diferente, una vez que se establece la vecindad de BFD los paquetes de de control dejan de ser enviados, y en su lugar utiliza un método de polling (consulta) como por ejemplo las estadisticas de paquetes enviados y recibidos en la interfaces. Ahora, no hay que poner tanta atención a este método ya que actualemtne no es soportado por Cisco y mucho más vendors.
Veamos un ejemplo de utilización con la siguiente configuración
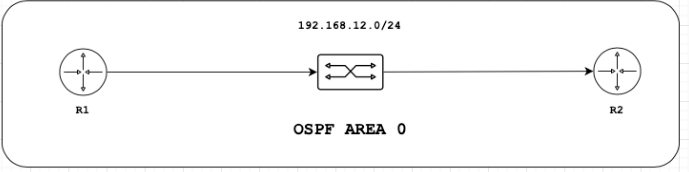
R1#!interface GigabitEthernet0/0 ip address 192.168.12.1 255.255.255.0 duplex auto speed auto media-type rj45!router ospf 10 network 192.168.12.0 0.0.0.255 area 0!R1#show ip ospf neighbor Neighbor ID Pri State Dead Time Address Interface192.168.12.2 1 FULL/DR 00:00:39 192.168.12.2 GigabitEthernet0/0R1#
R2#!interface GigabitEthernet0/0 ip address 192.168.12.2 255.255.255.0 duplex auto speed auto media-type rj45!router ospf 10network 192.168.12.0 0.0.0.255 area 0 R2#show ip ospf neighbor Neighbor ID Pri State Dead Time Address Interface192.168.12.1 1 FULL/BDR 00:00:38 192.168.12.1 GigabitEthernet0/0
Como se observa en ambos equipos la sesión de OSPF se encuentra establecida. Ahora, vamos a simular una falla en el link entre R1 y el switch. Es importante observar los times en ambos equipos.
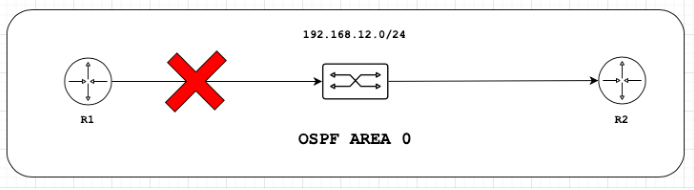
R1#*Feb 12 ==**20:50:40.589**==: %OSPF-5-ADJCHG: Process 10, Nbr 192.168.12.2 on GigabitEthernet0/0 from FULL to DOWN, Neighbor Down: Interface down or detached*Feb 12 ==**20:50:42.541**==: %LINK-5-CHANGED: Interface GigabitEthernet0/0, changed state to administratively down*Feb 12 ==**20:50:43.542**==: %LINEPROTO-5-UPDOWN: Line protocol on Interface GigabitEthernet0/0, changed state to down
R2#*Feb 12 ==**20:52:07.190**==: %OSPF-5-ADJCHG: Process 10, Nbr 192.168.12.1 on GigabitEthernet0/0 from FULL to DOWN, Neighbor Down: Dead timer expired
Para tratar de clarificar lo que estamos viendo en los logs, dejame extraer la siguiente información de Router 1.
R1#*Feb 12 20:50:40.589: %OSPF-5-ADJCHG: Process 10, Nbr 192.168.12.2 on GigabitEthernet0/0 from FULL to DOWN, Neighbor Down: Interface down or detached
Debido a que le falla ocurre entre en link de R1 y el switch la vecindad cae de forma inmediata, pero que sucede con Router 2 ?
R2#
*Feb 12 20:52:07.190: %OSPF-5-ADJCHG: Process 10, Nbr 192.168.12.1 on GigabitEthernet0/0 from FULL to DOWN, Neighbor Down: Dead timer expired
Como podemos observar el tiempo que transcurre para que R2 se de cuenta que la sesión de vecinos ha caido con OSPF es demasiado. La traducción de esto, es que muy probablemente mucho tráfico se haya perdido por el tiempo que el mismo protocolo utiliza para detectar fallas.
Ahora configuraremos BFD en ambos routers para ver la diferencia del funcionamiento
R1(config)#interface GigabitEthernet0/0R1(config-if)#bfd ? echo Use echo adjunct as bfd detection mechanism interval Transmit interval between BFD packets
R1(config)#interface GigabitEthernet0/0R1(config-if)#bfd interval ? <50-999> Milliseconds
En esta parte podemos especificar el intervalo de tiempo que transmitir los paquetes BFD
R1(config-if)#bfd interval 90 ? min_rx Minimum receive interval capability
Vamos a utilizar el valor menor permitido, en este caso 50 milisegundos.
El segundo valor a configurar es el intervalo mínimo de recepción (minimum receive interval). Este parámetro define cada cuánto tiempo esperamos recibir un paquete BFD desde el vecino.
R1(config-if)#bfd interval 90 min_rx 90 ? multiplier Multiplier value used to compute holddown!R1(config-if)#bfd interval 90 min_rx 90 multiplier 3
El último valor a configurar corresponde al holddown.Este concepto es similar a:
- Dead Interval en OSPF
- Holddown timers en otros protocolos
Define cuántos paquetes BFD pueden perderse antes de declarar la sesión DOWN.
Ahora, vamos a configurar los mismos parámetros en R2
R2(config)#interface GigabitEthernet 0/0 R2(config-if)#bfd interval 90 min_rx 90 multiplier 3
BFD ahora está activo y funcionando, pero todavía necesitamos configurar los protocolos para que realmente lo utilicen. A continuación se muestra cómo hacerlo para OSPF:
R1(config)#router ospf 1 R1(config-router)#bfd all-interfaces
R2(config)#router ospf 1 R2(config-router)#bfd all-interfaces
Verificación
El siguiente comando nos ayudará a verificar que nuestra vencidad de BFD se enuentra establecida
R1#show bfd neighbors NeighAddr LD/RD RH/RS State Int 192.168.12.2 1/1 Up Up Fa0/0
R1#show bfd neighbors details
IPv4 Sessions
NeighAddr LD/RD RH/RS State Int
192.168.12.2 3/3 Up Up Gi0/0
Session state is UP and using echo function with 90 ms interval.
Session Host: Software
OurAddr: 192.168.12.1
Handle: 1
Local Diag: 0, Demand mode: 0, Poll bit: 0
MinTxInt: 1000000, MinRxInt: 1000000, Multiplier: 3
Received MinRxInt: 1000000, Received Multiplier: 3
Holddown (hits): 0(0), Hello (hits): 1000(2914)
Rx Count: 2922, Rx Interval (ms) min/max/avg: 7/1092/877 last: 352 ms ago
Tx Count: 2916, Tx Interval (ms) min/max/avg: 6/1004/880 last: 494 ms ago
Elapsed time watermarks: 0 0 (last: 0)
Registered protocols: **OSPF CEF**
Uptime: 00:42:40
Last packet: Version: 1 - Diagnostic: 0
State bit: Up - Demand bit: 0
Poll bit: 0 - Final bit: 0
C bit: 0
Multiplier: 3 - Length: 24
My Discr.: 3 - Your Discr.: 3
Min tx interval: 1000000 - Min rx interval: 1000000
Min Echo interval: 90000
R1#
En la salida anterior podemos observar:
- La cantidad de paquetes BFD transmitidos y recibidos
- Los protocolos que actualmente dependen de BFD
Para demostrar su efectividad, a continuación simularemos una falla en el enlace. Nuevamente vamos a apagar el link entre R1 y el switch
R1(config)#interface gi 0/0 R1(config-if)#sh
R1(config-if)# *Feb 12 **==23:05:02.206==**: %OSPF-5-ADJCHG: Process 10, Nbr 192.168.12.2 on GigabitEthernet0/0 from FULL to DOWN, Neighbor Down: Interface down or detached *Feb 12 23:05:02.208: %BFD-6-BFD_SESS_DESTROYED: BFD-SYSLOG: bfd_session_destroyed, ld:3 neigh proc:OSPF, handle:1 act
Como se puede observar en Router 1 la caída ocurre a las 23:05:02.206
*Feb 12 **==23:06:42.584==**: %BFDFSM-6-BFD_SESS_DOWN: BFD-SYSLOG: BFD session ld:3 handle:1,is going Down Reason: ECHO FAILURE *Feb 12 23:06:42.589: %BFD-6-BFD_SESS_DESTROYED: BFD-SYSLOG: bfd_session_destroyed, ld:3 neigh proc:OSPF, handle:1 act *Feb 12 23:06:42.591: %OSPF-5-ADJCHG: Process 10, Nbr 192.168.12.1 on GigabitEthernet0/0 from FULL to DOWN, Neighbor Down: BFD node down
Mientras que en Router 2 la caida ocure 23:06:42.584
Cómo podemos observar el tiempo de detección de la caída ha sido mucho más rápdia con la utilización de BFD

Deja un comentario